
目录[-]
- 1.start-all.sh开启线程
- 2. -ls/-lsr 查看目录下的文件信息
- 3. –touchz 创建文件
- 4. –mkdir 创建文件夹
- 5. -text/-cat查看文件内容
- 6. -mv 移动/重命名
- 7. -cp 复制
- 8. -rm/-rmr 删除文件
- 9. -put 上传文件
- 10.-copyFromLocal 从本地复制
- 11 -moveFromLocal从本地移动
- 12. -getmerge 合并下载到本地
- 13. -setrep/-setrep -R/-setrep -R -w 设置副本数量
- 14. -du统计目录下个文件大小
- 15.-count统计文件(夹)数量
- 16. –chmod/-chmod -R 修改文件权限
- 17. hadoop jar 导jar在命令行运行
- 18、报告HDFS的基本统计信息
- 19、安全模式
- 20、将HDFS中的文件复制到本地系统中
1.start-all.sh开启线程
hadoop fs -ls hdfs://cloud4:9000/user (cloud4表示主机名 9000代表端口号 /就代表根目录 /user就是user文件夹)
hadoop fs -ls /user(hdfs://cloud4:9000可省略)
2. -ls/-lsr 查看目录下的文件信息
hadoop fs -ls / 查看根目录下文件与文件夹
hadoop fs -lsr / 递归查看根目录下所有文件与文件夹
hadoop fs -ls 默认查看hdfs下的/user/<当前用户> 例如:/user/root (很方便的)
3. –touchz 创建文件
可以创建一个文件
hadoop fs -touchz /hello (创建一个hello文件)
4. –mkdir 创建文件夹
(linux中创建多级目录 mkdir –p p表示parents)
可以创建一个或者多个文件夹(hadoop则不需要-p)
hadoop fs -mkdir /user (创建一个user文件夹 )
5. -text/-cat查看文件内容
hadoop fs -text /hello
hadoop fs -cat /hello
6. -mv 移动/重命名
该命令选项表示移动 hdfs 的文件到指定的 hdfs 目录中。后面跟两个路径,第一个表示源文件,第二个表示目的目录
hadoop fs -mv /hello /user(文件到文件夹:是移动)
hadoop fs -mv /hello /user/hello(文件到文件:是重命名)
7. -cp 复制
该命令选项表示复制 hdfs 指定的文件到指定的 hdfs 目录中。后面跟两个路径,第
一个是被复制的文件,第二个是目的地
hadoop fs -cp /user/hello /user/root
8. -rm/-rmr 删除文件
-rm:删除文件/空白文件夹
该命令选项表示删除指定的文件或者空目录
hadoop fs -rm /user/hello
-rmr:递归删除
该命令选项表示递归删除指定目录下的所有子目录和文件
hadoop fs -rm /user
9. -put 上传文件
该命令选项表示把 linux 上的文件复制到 hdfs 中
hadoop fs -put hadoop-env.sh /user
将当前linux目录下的hadoop-env.sh文件,上传到/user(hdfs服务器上的user目录下)
hadoop fs -put hadoop-env.sh /你叫起的名字(hello—文件名)
例如:hadoop fs -put hadoop-env.sh /hello
10.-copyFromLocal 从本地复制
用法与-put一样
hadoop fs -copyFromLocal hadoop-env.sh /user
11 -moveFromLocal从本地移动
该命令表示把文件从 linux 上移动到 hdfs 中
hadoop fs -moveFromLocal /home/repine/hehe.txt /user
12. -getmerge 合并下载到本地
该命令选项的含义是把 hdfs 指定目录下的所有文件内容合并到本地 linux 的文件中
hadoop fs -getmerge /user /home/repine/abc.txt 表示把user目录下所有文件内容复制到linux下 /home/repine/abc.txt中
13. -setrep/-setrep -R/-setrep -R -w 设置副本数量
该命令选项是修改已保存文件的副本数量,后面跟副本数量,再跟文件路径
hadoop fs -setrep 2 /user/hehe.txt 设置/user/hehe.txt副本数量为2
如果最后的路径表示文件夹,那么需要跟选项-R,表示对文件夹中的所有文件都修改副本
hadoop fs -setrep -R 2 /user 设置/user下所有文件(不是文件夹)的副本数量为2
还有一个选项是-w,表示等待副本操作结束才退出命令
hadoop fs -setrep -R -w 1 /user/hehe.txt
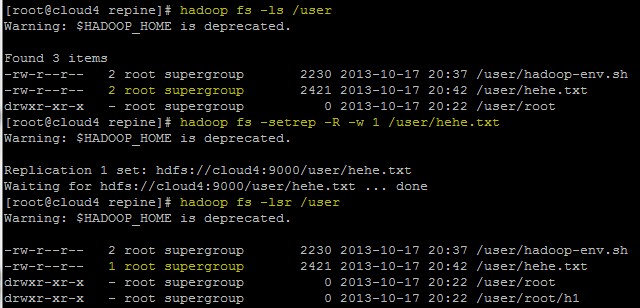
14. -du统计目录下个文件大小
hadoop fs -du / 查看根目录下的各个文件的大小
hadoop fs -dus / 汇总统计目录下所有文件的总大小(也就是当前文件夹的大小)
15.-count统计文件(夹)数量
hadoop fs -count /usr 递归统计当前文件下的所有信息:数字代表(文件夹总数量、文件总数量、文件总大小信息)
hadoop fs -lsr /usr 验证信息
16. –chmod/-chmod -R 修改文件权限
该命令选项的使用类似于 linux 的 shell 中的 chmod 用法,作用是修改文件的权限
hadoop fs - chmod 777 /user/hehe.txt 修改该文件的权限
如果加上选项-R,可以对文件夹中的所有文件修改权限
hadoop fs – chmod -R 777 /user 修改该文件夹下所有文件的权限
17. hadoop jar 导jar在命令行运行
//打包运行程序必备宝典
job.setJarByClass(WordCountApp.class);
在linux下 :
hadoop jar /linux下路径/XXX.jar /hadoop执行jar的文件或者文件夹 /hadoop下存放目录
18、报告HDFS的基本统计信息
bin/hadoop dfsadmin -report
19、安全模式
bin/hadoop dfsadmin -safemode leave/enter/get/wait
20、将HDFS中的文件复制到本地系统中
bin/hadoop dfs -get in getin
将HDFS中的in文件复制到本地系统并命名为getin
转自:http://my.oschina.net/repine/blog/268278#OSC_h2_2



相关推荐
大数据课程自备资料:Hadoop安装指南 + Linux常用操作命令
hadoop 全套环境搭建指南,三台虚拟机环境准备 linux基础及shell增强 大数据集群环境准备 zookeeper介绍及集群操作 网络编程
EasyHadoop集群部署文档\Hadoop常用命令\hadoop大数据架构生态技术简介\Hadoop权威指南\Hadoop实战
第2篇(基础实践部分)主要详细介绍了cemOs系统的安装和集群的搭建、Hadoop集群的常用命令及管理应用等;第3篇(项目实训部分)主要以实际项目开发为例,从易到难,对源程序进行了详细解释。 本书以详细的实践操作介绍...
大数据常用软件安装指南 包括Hadoop、Hive、Spark、Storm、Flink、HBase、Kafka、Zookeeper、Flume、Sqoop等技术的学习 Hadoop 分布式文件存储系统 —— HDFS 分布式计算框架 —— MapReduce 集群资源管理器 —— ...
大数据常用软件安装指南 一、Hadoop 分布式文件存储系统:HDFS 分布式计算框架:MapReduce 集群资源管理器:YARN 单机伪集群环境搭建 集群环境搭建 常用 Shell 命令 Java API 的使用 基于 Zookeeper 搭建 Hadoop 高...
大数据常用软件安装指南 一、Hadoop 分布式文件存储系统 —— HDFS 分布式计算框架 —— MapReduce 集群资源管理器 —— YARN Hadoop 单机伪集群环境搭建 Hadoop 集群环境搭建 HDFS 常用 Shell 命令 HDFS Java API ...
大数据常用软件安装指南 一、Hadoop 分散文件存储系统 —— HDFS 多元计算框架——MapReduce 集群资源管理器 —— YARN Hadoop单机伪集群环境搭建 Hadoop 云服务环境搭建 HDFS使用Shell命令 HDFS Java API的使用 ...
'[IT18掌www.it18zhang.com]004.Ubuntu常用命令.pptx' '[IT18掌www.it18zhang.com]017.Hadoop 架构分析之启动脚本总结.pptx' '[IT18掌www.it18zhang.com]Spark Graph编程指南.pptx' '[IT18掌www.it18zhang.com]005....
HDFS核心内容及命令-2020 hive安装 hive语法和常用函数 Kafka安装 kylin安装 mapreduce调优指南 sqoop安装 二、架构篇 Flink-1.11 Hive集成与批流一体 ClickHouse在苏宁用户画像场景的实践 优酷大数据 OLAP 技术...